
Creative Prompters
애플의 논문 : LLM in a Flash 논문 요약 본문
논문은 아래에 제가 만든 논문봇 GPTs로 요약하였습니다.
https://chat.openai.com/g/g-NMFiPqOX4-jeongmal-wanbyeoghan-nonmun-yoyag-seolmyeong-api-5modeu
ChatGPT - 🧑🏫 정말 완벽한 논문 요약 설명 (API + 5모드)
🧑🏫 비 전공자도 쉽게 이해 할 수 있는 친절한 논문 설명 🧑🏫 (/Intro, /Analysis, /Results, /Functions, /Code Implementation)✍️ arXiv 논문 번호나 링크와 함께 /intro를 입력하시거나, 👩🎓논문 파
chat.openai.com
LLM in a flash: Efficient Large Language Model Inference with Limited Memory
"LLM in a Flash: 제한된 메모리에서의 효율적인 대형 언어 모델 추론 소개"
선생님의 모두를 위한 논문 요약
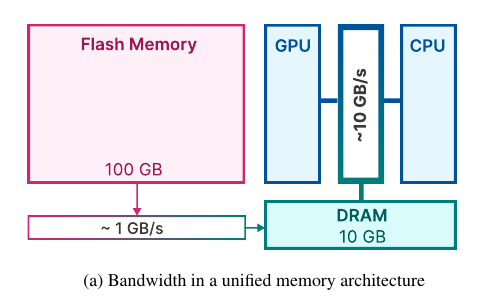
이 연구 논문은 우리가 말하는 것을 컴퓨터가 이해하고 대답하는 거대한 프로그램, 즉 '대형 언어 모델(LLM)'이 작은 기기에서도 잘 작동하도록 하는 새로운 기술을 만든 것에 대해 설명해요. 우리가 많은 양의 정보를 저장해 둔 큰 창고인 '플래시 메모리'에 이 프로그램의 규칙과 명령어(매개 변수)를 저장해두고, 컴퓨터가 '계산하고 생각하는 뇌'(DRAM)가 필요로 할 때만 꼭 필요한 작은 부분을 빠르게 옮겨와서 작업을 할 수 있게 해요.
이 기술에는 '윈도잉'과 '행-열 번들링'이라는 두 가지 중요한 방법이 있어요. '윈도잉'은 컴퓨터가 이미 생각했던 것들을 다시 사용해서 시간을 절약하는 거예요. '행-열 번들링'은 큰 창고인 플래시 메모리에서 필요한 정보를 더 크고 연속적인 덩어리로 모아서 빠르게 뇌로 옮기는 방법이에요. 이렇게 하면 기존의 방법보다 4배에서 25배까지 빠른 속도로 컴퓨터가 생각하고 답변을 할 수 있어요.
연구에서는 이런 방법을 이용해서 기존의 컴퓨터 뇌(DRAM)가 처리할 수 있는 양의 2배까지도 거대한 프로그램을 실행할 수 있게 했어요. 이로 인해 작은 기기에서도 어려운 언어 처리 작업을 할 수 있는 문이 넓혀지게 되었고, 많은 기기에서 이 전략을 사용할 수 있게 되는 것을 보여줘요.
초록 요약
"LLM in a Flash: 제한된 메모리에서의 효율적인 대형 언어 모델 추론"이라는 연구 논문은 특히 제한된 DRAM 용량을 가진 장치에서 대형 언어 모델 (LLM)을 실행하는 도전에 대한 고찰입니다. 이 논문은 모델 매개 변수를 플래시 메모리에 저장하고 필요할 때 DRAM으로 로드하여 효율적인 LLM 추론을 위한 새로운 방법을 제시합니다. 이 접근 방식은 "윈도잉"과 "행-열 번들링"이라는 두 가지 주요 기술을 포함합니다. 윈도잉은 이전에 활성화된 뉴런을 재사용하여 데이터 전송을 줄이고, 행-열 번들링은 플래시 메모리에서 읽은 데이터 덩어리의 크기를 증가시킵니다. 이러한 전략들은 사용 가능한 DRAM 크기의 두 배까지의 모델을 실행할 수 있게 하며, 표준적인 CPU 및 GPU 로딩 방법과 비교하여 각각 4-5배 및 20-25배의 추론 속도 증가를 달성합니다.
소개 및 배경
GPT-3와 같은 LLMs는 다양한 자연어 처리 작업에서 인상적인 성능을 보여주었습니다. 그러나 수십억 개의 매개 변수를 포함하는 그들의 큰 크기는 특히 제한된 DRAM을 갖는 장치에서의 효율적인 로딩과 실행에 대한 도전을 제기합니다. 현재의 표준적인 방법은 추론을 위해 전체 모델을 DRAM에 로드하는 것이며, 이는 많은 장치에서 실행할 수 있는 최대 모델 크기를 제한합니다.
이에 대처하기 위해 논문은 DRAM보다 훨씬 더 많은 용량을 가진 플래시 메모리를 활용하는 방법을 제안합니다. 논문의 방법론은 LLMs가 특히 FeedForward Network (FFN) 레이어에서 높은 희소성을 나타내는 관찰을 기반으로 하며, 이를 활용하여 플래시 메모리 상호 작용과 메모리 관리를 최적화합니다.
핵심 개념
- DRAM (Dynamic Random-Access Memory): 고속 데이터 액세스를 위해 컴퓨터 및 장치에서 사용되는 메모리 유형.
- Flash Memory: 데이터 저장에 사용되는 비휘발성 메모리로, DRAM에 비해 높은 용량을 제공하지만 속도는 낮습니다.
- LLMs의 희소성: 모델 매개 변수에서 많은 수의 제로 또는 거의 제로 값이 존재하는 것으로, 효율적인 데이터 처리에 활용될 수 있습니다.
- 윈도잉: 오직 최근의 몇 토큰에 대한 매개 변수만 로드하는 기술로, I/O 요청 수를 줄입니다.
- 행-열 번들링: 플래시 메모리에서 더 큰, 더 연속적인 덩어리로 데이터를 저장하고 읽는 방법으로, 처리량을 향상시킵니다.
연구의 목적
이 논문은 모델 매개 변수를 플래시 메모리와 DRAM 간의 지능적인 저장 및 전송으로 효율적으로 실행할 수 있는 방법을 개발하는 것을 목표로 합니다. 이 접근 방식은 자원 제한 환경에서 고급 LLMs의 사용을 가능하게 하여 그들의 적용 가능성과 접근성을 확장하기 위한 것입니다.
"LLM in a Flash: 제한된 메모리로 효율적인 대형 언어 모델 추론의 결과 및 함의"
주요 발견
감소된 대기 시간: 제안된 방법은 플래시 메모리에서 모델 매개 변수를 DRAM으로 로드하는 데 대한 대기 시간을 크게 줄였습니다. 예를 들어 OPT 6.7B 모델의 경우, 창 크기를 5로 사용하면 총 메모리 관련 대기 시간이 토큰 당 190ms 미만으로 감소했습니다. 이는 기본 방법보다 큰 개선을 나타냅니다. 기본 방법은 토큰 당 약 2330ms가 필요했습니다. 마찬가지로 Falcon 7B 모델의 경우, 토큰 당 대기 시간은 기본 방법의 2330ms 대비 약 250ms였습니다.
증가된 처리량: 창 크기 및 행-열 번들링과 같은 전략을 구현함으로써 플래시 메모리에서 데이터 전송의 처리량이 크게 증가했습니다. 이는 로드된 데이터 청크의 크기를 최적화하고 전송되는 데이터 양을 최소화함으로써 달성되었습니다.
메모리 사용 최적화: 이 연구는 뉴런 데이터 관리를 위한 슬라이딩 창 및 최적화된 메모리 관리 전략과 같은 기술을 사용하여 DRAM의 효율적인 활용을 시연했습니다. 이를 통해 사용 가능한 DRAM의 크기의 두 배까지 모델을 실행할 수 있었습니다.
성능 지표: 이 연구는 해당 방법이 다양한 모델 (OPT 6.7B 및 Falcon 7B) 및 하드웨어 설정 (Apple M1 Max 및 NVIDIA GeForce RTX 4090을 장착한 Linux 머신)에 대해 효과적임을 보여주었습니다.
AI 분야 및 실제 응용 프로그램에 대한 함의
자원 제한 환경에서 LLM 사용 확장: 제한된 DRAM을 가진 장치에서 대형 모델을 실행할 수 있는 능력은 리소스가 제한된 다양한 장치에 고급 AI 응용 프로그램을 배치하는 새로운 가능성을 열어줍니다.
모델 추론의 효율성: LLM 추론의 대기 시간 크게 감소 및 처리량 향상은 특히 실시간 처리가 필요한 시나리오에서 이러한 모델을 활용하는 보다 효율적이고 확장 가능한 접근 방식을 시사합니다.
향후 연구 방향: 이 연구는 제한된 환경에 대한 LLM 최적화 연구에 선례를 제시합니다. 하드웨어 특성을 알고리즘 개발에 고려하는 중요성을 강조하며 이 도메인에서 새로운 방법론에 영감을 줄 수 있습니다.
고급 AI 모델의 더 넓은 접근성: 대형 모델을 다양한 장치에서 실행할 수 있게 함으로써 이 연구는 고급 AI 도구를 활용할 수 있게 하여 작은 조직 및 개인이 강력한 AI 도구를 활용할 수 있게 할 수 있습니다.
한계 및 개선 가능한 영역
이 방법은 모델 크기가 사용 가능한 DRAM을 초과하는 시나리오를 특정 대상으로 하지만, 이것은 모든 사용 사례에 적용되지 않을 수 있습니다.
이 연구는 메모리 및 데이터 전송 효율성을 개선하는 데 중점을 두었으며, 새로운 제약 조건 하에서 연산 효율성 및 모델 정확도에 대한 추가 최적화 여지가 있습니다.
이러한 기술을 다른 유형의 신경망 아키텍처나 다른 하드웨어 구성에 적용하는 데 추가적인 어려움이 있을 수 있습니다.
결론적으로, 이 논문은 메모리 제한 하에서 대형 언어 모델 추론에 대한 혁신적인 접근 방식을 제시하며, 효율성을 크게 향상시키고 다양한 실제 시나리오에서 LLM 응용 프로그램의 잠재력을 확대하는 것을 시연하였습니다.
'AI 세계 심층탐구 > 데이터와 AI 이론공부' 카테고리의 다른 글
| "ImageNet Classification with Deep Convolutional Neural Networks" (1) | 2023.12.28 |
|---|
