
Creative Prompters
생성형 이미지와 워터마크 기술, 논의(2); 창과 방패 본문
https://cprompters.tistory.com/20
생성형 이미지와 워터마크 기술, 논의
AI 생성 아트와 저작권 문제는 현재도 진행 중인 뜨거운 이슈입니다. 생성형 이미지와 같은 AI 생성물의 합법성에 대한 불안이 널리 퍼져 있으며, 이에 대한 정보를 찾는 사람들이 많습니다. 실제
cprompters.tistory.com
지난 시간에는 4가지 기술을 소개드렸습니다.
1.ChatGPT 판별을 위한 텍스트 워터마크
2. MIT 인공지능연구소(CSAIL)의 포토가드(Photo Guard)
3. 구글의 '보이지 않는' 디지털 워터마크 SynthID
4. MIST 프로젝트
최근 워터마크 기술의 가장 뜨거운 핵심은 이것 입니다.
1. 유명인과 정치인들의 이미지를 악용한 딥페이크를 어떻게 막을 것이냐
2. 창과 방패 : 지워지지 않는 워터마크를 만드려는 사람과 없애려는 시도

1. 민주주의를 뒤흔드는 선거 Deepfakes
정치인들의 딥페이크는 특히 민주주의와 선거의 근간을 뒤흔들 수 있기 때문에 정부에서도 매우 민감하게 반응하고 있습니다. 위의 사진의 인물인 영국 노동당의 지도자인 키어 스타머의 목소리로 직원들을 구두로 학대하는 것처럼 유포된 영상은 민간 부문과 영국 정부의 분석에 의해 딥페이크로 판명되었고 큰 논란을 일으켰습니다. 물론, 우리나라도 앞으로 이러한 논란을 피해가긴 힘들 것 같기에 대비가 필요할 것 같습니다.
당연히 새 대통령 선거를 준비하고 있는 미국에서도 이 문제는 큰 화두입니다.
Meta and X questioned by lawmakers over lack of rules against AI-generated political deepfakes
US Sen. Amy Klobuchar of Minnesota and U.S. Rep. Yvette Clarke of New York sent a letter Thursday to Meta CEO Mark Zuckerberg and X CEO Linda Yaccarino expressing “serious concerns” about the emergence of AI-generated political ads on their platforms a
apnews.com
Meta와 X는 AI로 생성된 정치적 딥페이크에 대한 규칙이 부족하여 미국의 의원들로부터 질문을 받았습니다. 그리고 올해 초 하원 법안 은 선거 광고에 AI 생성 이미지나 비디오가 포함된 경우 라벨을 요구하도록 연방 선거법을 개정하는 법안도 제출되었습니다.
YouTube wants to launch an AI-powered tool that lets you sound like your favorite singer, report says
The launch has been delayed by ongoing talks with record companies about the rights needed to train YouTube's AI software, Bloomberg reported.
www.businessinsider.com
그러나 한편으로는 급진적인 저작권 개념의 삭제나 개혁을 원하는 목소리도 생겨나고 있는 것 같습니다. 유튜브는 사용자가 유명 음악가의 목소리를 사용해 노래를 만들 수 있는 AI 기능을 출시하려고 했지만, 아직 필요한 권리를 얻지 못했다는 보도가 있었습니다. 이 경우 수익 분배라던지 저작권이 거의 지켜지지 않을 수 있어 우려의 목소리가 큽니다.
2. 생성형 AI 콘텐츠 어떻게 구분하죠? 창과 방패의 싸움
그렇다면 이러한 문제를 해결하기 위해서는 무분별한 데이터 학습을 통한 저작권 침해 혹은 변형 생성을 막을 수 있도록 하거나 AI로 생성 된 영상인지를 '판별'할 수 있느냐 일텐데요. 제가 2번에서 소개드릴 내용은 이러한 문제 해결을 위해 워터마크 기술, 라벨링의 적용 그리고 추가적으로 학습 된 내용의 삭제를 통한 연구 사례입니다.
워터마크 기술의 경우 'Washing out' 즉 워터마크를 없애는 기술과 'Data poisoning' 기술이 현재 가장 활발히 관심을 끌고 있습니다. 'Data poisoning' 기술의 경우는 무단 학습한 AI 자체를 망가뜨릴 수 있다고 하여 화제가 되었는데요 반면, 현재로서는 어떤 워터마크라도 없애는 것은 더 간단하다는 의견이 더 우세한 것으로 알려져 있습니다.
Watermark로 arxiv.org에 직접 검색해본 결과 총 673개의 논문 중 154개가 2023년에 씌여졌습니다.
2022년 93개 2021년 86개 였던 것에 비하면 2배 가까히 증가한 수치인데요! 그 만큼 관심이 높아진 기술이라고도 할 수 있겠습니다.
1. Tik tok : AI 생성 콘텐츠 분류 및 라벨링 적용
https://newsroom.tiktok.com/en-us/new-labels-for-disclosing-ai-generated-content
New labels for disclosing AI-generated content
As more creators take advantage of Artificial Intelligence (AI) to enhance their creativity, we want to support transparent and responsible content creation practices. As part of that effort, we conti
newsroom.tiktok.com
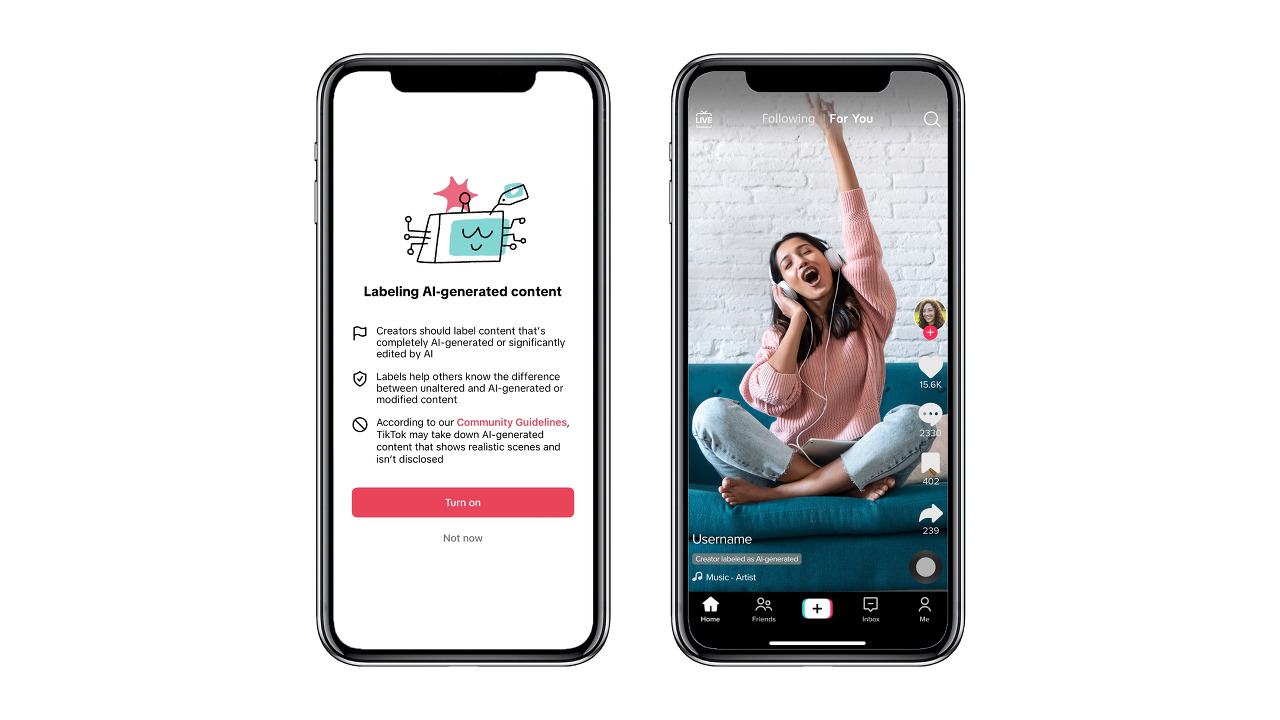
라벨링을 통해 AI가 생성한 영상인지 아닌지를 알려준다면 일단 혼란이 줄어들겠죠.
틱톡은 AI 생성 콘텐츠에 자동으로 레이블을 지정하는 방식을 정책으로 채택하려고 하고 있습니다. "우리는 AI를 사용하여 편집되거나 생성된 것으로 감지된 콘텐츠에 자동으로 적용할 'AI 생성' 라벨 테스트를 시작할 예정입니다"라고 발표하였습니다. 콘텐츠 생성자가 자발적으로 라벨을 달도록 우선 권장하며, 자동으로 판별 된 경우에 알림 문구를 띄우도록 시도하고 있습니다.
오용을 방지하기 위해 분류 규칙이나 기술에 대한 세부 사항은 공유되지 않았지만, ChatGPT가 알려 준 일반적으로 AI 콘텐츠를 분류하는 기술은 대체로 다음과 같은 카테고리로 나눌 수 있습니다:
- Text Analysis Algorithms: 자연어 처리(NLP) 알고리즘을 사용하여 텍스트가 AI에 의해 생성되었는지 판단합니다.
- Metadata Analysis: 콘텐츠에 포함된 메타데이터를 분석하여 AI 생성 여부를 판단합니다.
- Image Recognition: 이미지나 비디오 콘텐츠의 경우, 딥 러닝 기반의 이미지 인식 알고리즘을 사용할 수 있습니다.
- Behavioral Analysis: 콘텐츠 생성 패턴, 사용자 행동 등을 분석하여 AI 생성 여부를 판단합니다.
- Digital Forensics: 디지털 포렌식 기술을 사용하여 콘텐츠가 AI에 의해 조작되었는지 여부를 판단합니다.
- Crowdsourcing: 일반 사용자나 전문가의 의견을 모아 판단하는 방법도 있습니다.
- Hybrid Approaches: 위의 여러 방법을 조합하여 더 정확한 판단을 내릴 수 있습니다.
그리고 왜 'AI Generated'라는 용어로 사용하는지 알고 싶으시다면 아래의 관련 논문을 참고하세요!
관련 논문 원본
What label should be applied to content produced by generative AI? : https://osf.io/preprints/psyarxiv/v4mfz
2. Washing out tool : 눈에 보이지 않는 워터마크를 모두 제거하는 기술
메릴랜드 대학교의 컴퓨터 과학 교수인 Soheil Feizi는 인공지능을 이용한 디지털 워터마킹에 대한 현 상황을 직설적으로 언급했습니다. 그는 “현재 우리에게는 신뢰할 수 있는 워터마킹이 없다”며 모든 워터마킹 방식이 실패했다"라고 주장했습니다.
연구진은 '눈에 보이지 않는' 주요 워터마크를 모두 제거했다는 논문을 발표하였고, 이 기술을 '세척(washing out)'이라고 명명하였습니다.
연구진은 최근 연구를 통해 '낮은 변동(low perturbation)' 워터마크, 즉 눈에 보이지 않는 워터마크에 대한 테스트를 진행했으며 평가는 냉철했습니다 "현재로서는 희망이 없다."
이 연구는 워터마킹 기술에 대한 의문과 워터마킹만으로는 충분하지 않으며, 더욱 강력한 인증 도구와 전략이 필요함을 강조하며, 어떠한 도전과 기회를 가져다주는지를 잘 보여줍니다.
https://www.wired.com/story/artificial-intelligence-watermarking-issues/
Researchers Tested AI Watermarks—and Broke All of Them
A research team found it's easy to evade current methods of watermarking—and even add fake watermarks to real images.
www.wired.com
3. 무단 학습 AI를 파괴하는 Data poisoning 도구 Nightshade

Nightshade는 생성적 AI 모델이 무단으로 아티스트의 작품을 사용하는 것을 막기 위해 만들어진 도구입니다.
이 도구는 아티스트의 작품에 눈에 보이지 않는 픽셀 변경을 추가하여, 저작권이 있는 이미지를 생성형 이미지로 변경하여 생성하려고 시도하면, 마치 독이 퍼진 것 처럼 망가진 결과를 생성하게 됩니다.
정말 이 기능이 앞에서 소개한 Washing out 등의 기술을 무효화 하고 효과적이라면, 특히 DALL-E, Midjourney, Stable Diffusion과 같은 이미지 생성 AI 모델에 영향을 미칠 수 있게 될 예정입니다.
해외 온라인 커뮤니티에서는 이것이 아예 AI 모델 자체를 오염시킬 수 있다고 하여 정말 저작권을 지킬 수 있는 파괴적인 수단과 같다, 기대된다는 의견과 더불어 이 도구는 이론적으로만 가능하지 실제 세계에서는 정말 작동 가능성이 없다. 단지 AI에 대한 사람들의 두려움으로부터 빨리 돈을 벌려고 노력하고 있을 뿐이다 라는 의견들이 존재합니다.
관련 논문 원본
Prompt-Specific Poisoning Attacks on Text-to-Image Generative Models: https://arxiv.org/abs/2310.13828
4. Unlearning 기술을 통한 학습 데이터 삭제

이건 영상 쪽은 아니고 텍스트 쪽에서만 도움이 될 수도 있을 것 같습니다. 이미 학습 된 데이터에서 특정 구체적인 부분만 삭제하거나 대체해서 말할 수 있게 한다면, 저작권 침해를 방지할 수 있겠죠. 예를들어 이 연구에서는 해리포터 소설을 통해 실험을 진행했습니다. 생성형 AI가 호그와트는 신비한 학원으로 해리는 존으로 이름을 바꾸어 출력되게 만들었습니다.
이 Unlearning 기술은 정확히는 Dictionary를 통해 예측 레이블을 만들고 '일반적인 표현으로 대체' 하는 것에 가깝습니다. 예를 들어, 민감한 정보나 잘못된 정보가 모델에 포함되었을 경우, Unlearning은 해당 데이터와 가장 관련 있는 토큰을 식별하고, 이를 일반적인 표현으로 대체합니다. 이 과정을 통해 기존 모델을 미세조정하게 됩니다.
그러나 이 기술도 완벽하지 않습니다. 일단 모델이 일부 데이터를 "잊어버리게" 하는 것은 매우 복잡한 과정이며, 이로 인해 모델의 성능이 떨어질 수도 있습니다. 이 기술을 사용하면 원치 않는 부작용으로 모델이 다른 훈련 데이터를 잊어버릴 수도 있다고 합니다.
그리고 추가적으로, 이를 해결하기 위해 미세조정이 들어갈 경우 Jail break가 쉽게 일어날 수 있다는 연구 결과도 예전에 뉴스레터를 통해 소개드린 바 있습니다.
https://llm-tuning-safety.github.io/
LLM Finetuning Risks
Paper Overview Optimizing large language models (LLMs) for downstream use cases often involves the customization of pre-trained LLMs through further fine-tuning. Meta's open release of Llama models and OpenAI's APIs for fine-tuning GPT-3.5 Turbo on custom
llm-tuning-safety.github.io
관련 논문 원본
Who’s Harry Potter? Approximate Unlearning in LLMs : https://arxiv.org/pdf/2310.02238.pdf
결과적으로 말씀드리자면, 기술적으로 아직까지 워터마크 등을 통해서 AI 학습이나 변형 생성을 막는 방법은 연구중입니다. 따라서, 현재로서 할 수 있는 일은 정책적인 방향을 잘 잡아야 할텐데요. 이를 미국에서는 국가 위기까지로도 고려하고 있으며 UN에서도 따로 AI 관련 기구를 창설할 예정입니다. 물론 유럽이나 다른 국가들도 발빠르게 보강 정책을 추진하고 있습니다. 저는 개인적으로 적어도 이미지와 영상물에서는 AI로 생성한 생성물이라는 라벨의 강제화와 틱톡의 사례가 다른 플랫폼에도 적용되지 않을까 생각하고 있습니다. 그러나 이에 따른 문제는 어떤 것이 있을지 함께 의논해보면 좋은 주제일 것 같습니다. 여러분의 생각은 어떠세요? 읽어주셔서 감사합니다!!

'AI 법률과 정책 > 정책 이슈 공유' 카테고리의 다른 글
| OECD.AI 에서 만든 AI 정책 검색기; SAI: Search engine for AI policy 리뷰 (2) | 2023.10.17 |
|---|---|
| State of AI Report 2023 (0) | 2023.10.16 |
| Gen AI 비즈니스 리포트(Business Reports) 모음 (12) | 2023.10.01 |
| [CP]AI 뉴스레터[6~9회차] 정리 및 논평 (0) | 2023.09.30 |
| [CP]AI 뉴스레터[1~5회차] 정리 및 논평 (1) | 2023.09.30 |


